В подавляющем большинстве случаев социолог использует тот или иной способ выделения из большой совокупности явлений и объектов изучения некоторую их часть в надежде, что на этой выборочной совокупности могут быть выявлены свойства объекта исследования в целом. 19
19 В отличие от идеализированного обекта исследования, как определенной области социальной реальности, содержащей предмет изучения, здесь имеется ввиду эмпирический объект: конкретные индивиды, группы, организации, регионы, локализованные во времени и пространстве.
Тип и способы выборки прямо зависят от целей исследования и его гипотез. Чем конкретнее цель, чем яснее сформулированы гипотезы, тем правильнее будет решен вопрос о выборе.
Наиболее строгие требования предъявляются к выборкам десриптивных и аналитико-экспереминтальных исследваний, наименее строгие – к исследованиям по разведывательному плану. В последнем случае отбор «единиц наблюдения» на объекте подчиняется довольно простым правилам: следует выделять полярные группы по существенным для анализа критериям.

Численность таких несистематических выборок строго не определяется. Все зависит от состояния полученной информации. Наблюдение или опрос в таком исследовании продолжаются до тех пор, пока не обнаружится, что получится информация, достаточно разнообразная для формулировки гипотез. Следовательно, состав и объем выборки заранее не фиксируется, а устанавливаются опытным путем по мере развития исследования.
В исследовании дескриптивного плана вборка, напротив, должна быть строго репрезентативной. 20
20 Мы рассматриваем лишь принципиальные проблемы выборочных исследований. Методы и процедуры осуществления выборок разного типа см. [12. Гл. V; 118; 128; 196. С. 31-38; 198. Гл. III; 218.
Гл VI; 262. Ч.1; 287], а также в прил. 2 «Аннотированный список литературы»
Требования репрезентативной выборки означают, что по выделенным параметрам (критериям) состав обследуемых должен приближаться к соответствующим пропорциям в генеральной совокупности. Между тем, строго репрезентативную выборку по всем важным для проблематики исследования параметрам обеспечить невозможно, и поэтому следует гарантировать репрезентацию по главному направлению анализа данных.
Прежде всего, надо уяснить, какие из имеющихся сведений о характеристиках генеральной совокупности существенны для целей исследования. Во многих случаях это половозрастной, социально-профессиональный, имущественный состав обследуемых, их пространственная локаклизация.
Половозрастная структура «замыкает» на себя многие показатели семейного состояния, уже известные по другим данным. Возраст содержит указания на жизненный опыт и, как правило, не рабочий или профессиональный стаж. Социально-профессиональные, социально-статусные характеристики — это свидетельства о различиях в системе реального положения людей и их особых интересов, позиций.
10 реальных способов замотивировать сотрудников / Нематериальная мотивация персонала 16+
Пространственная локализация (по территории, подразделениям предприятий и учреждений, по другим административным и производственным «локалам») важна и с точки зрения особенностей условий этой деятельности (например, центр и периферия, основные и вспомогательные службы), и с точки зрения адресности итоговых выводов и рекомендаций, которые должны быть «привязаны» к административным или производственным ячейкам, имеющим четкие границы и часто самоуправляемым. В сочетании трех названных параметров — половозрастной структуры, социального состава, пространственной локализации — можно, как правило, быть уверенным, что выборка будет представительна для анализа многих социальных проблем. Понятно, что это правило имеет исключения в зависимости от конкретных условий и особых целей исследования (например, в этнически неоднородной среде существенно иметь в виду репрезентацию по критерию национальной принадлежности).
Мера подобия выборочной модели структуре генеральной совокупности оценивается ошибкой выборки, а пределы допустимой ошибки опять-таки зависят от цели исследования.
Иногда требуется повышенная надежность, как это имеет место в экономических и демографических обследованиях, например при переписях населения. Здесь существенные ошибки оборачиваются миллионными потерями материальных ресурсов и просчетами планирования.21
21 Аккуратная репрезентативная территориальная выборка в современной России требует систематических коррекций. Это связано с тем, что территориальные административные границы (именно они являются основами официальной статистики населения) формировались Для целей, не совпадающих с социально-исследовательскими и помимо того состав и структура населения в периоды реформации неустойчивы. Как показывает М. С. Косолапов [128], достоверные расчеты общенациональной и региональных представительных выборок — сложная исследовательская задача. Экономная выборка предполагает также аккуратные расчеты маршрутов исследователей (интервьюеров и др.), что составляет особую проблему в данном регионе.
Гораздо чаще социологические обследования проводятся для уяснения общих тенденций, общей ориентировки в сфере социальной политики.
Весьма полезна следующая приблизительная оценка надежности результатов выборочного обследования [301. С. 36].22
22 Формулы расчета ошибок выборки см. в литературе, указанной в сноске 19.
Повышенная надежность допускает ошибку выборки до 3%, обыкновенная — до 3—10% (доверительный интервал распределений на уровне 0,03—0,1), приближенная —от 10 до 20%, ориентировочная — от 20 до 40%, а прикидочная — более 40%.
В аналитических и экспериментальных исследованиях проблема статистической репрезентативности выборки оказывается второстепенной в сравнении с необходимостью обеспечить качественное представительство изучаемых социальных объектов,
Рассмотрим следующий пример. В изучении образа жиз* ни населения некоторого города мы, следуя правилам дескриптивного обследования, хотим обеспечить представительство всех групп населения соответственно их пропорциям в составе генеральной совокупности с отклонением ±5% от истинного распределения. Такая выборка, представительная в качественном отношении, будет также и статистически репрезентативной, но следует решить, нужно ли это.
Напомним, что репрезентативные выборки необходимы лишь в том случае, если целью исследования является получение суммарных данных в отношении изучаемого объекта в целом. В нашем примере — это все население данного города. Тогда в выводах социолог имеет право сообщить, что в среднем горожане так-то оценивают различные условия жизни и деятельности, в среднем такая-то доля населения проявляет высокую активность в таких-то видах деятельности, а такая-то — низкую и т. п. Но с практической точки зрения, не говоря уже о теоретических задачах изучения образа жизни, нам гораздо важнее выявить специфику условий и образа жизни различных групп населения и в том числе тех, которые, будучи малочисленными, нуждаются в специальном внимании.
Допустим, что в составе населения города имеется 370 ветеранов Отечественной войны. Чтобы получить более или менее достоверную информацию об условиях их жизни и их проблемах, надо обеспечить должное численное представительство этой категории граждан в выборочной совокупности.
Но поскольку выборка статистически репрезентативна, то при численности населения города, скажем, в 100 тыс. и численности выборочной совокупности в 2 тыс., т. е. при двухпроцентной выборке, доля ветеранов в выборочной совокупности составит 60 человек. Много это или мало?
Возможно, этой численности достаточно для того, чтобы сделать статистически достоверные заключения о простейших частных показателях условий их жизни, например об уровне обеспеченности жилищем ветеранов войны, в сравнении со среднестатистическими показателями на всю выборку населения города. Но как только мы захотим углубить анализ, мы обнаружим, что численность подвыборки ветеранов явно мала.
К примеру, важно установить, какова доля ветеранов войны, проживающих в отдельной квартире и без семьи, т. е. одиноких. В таком случае придется составить табличку размерностью 2X2 (две градации «проживают с семьей» и «одиночки» 4- две градации по критерию наличия своей комнаты или квартиры). В каждой клеточке этой таблицы может быть в пределе по 15 единиц наблюдения (60:4=15).
Конечно, реальное распределение окажется иным. Так, ветеранов-одиночек, не имеющих собственной комнаты, не будет вовсе. Зато одиночек, проживающих в отдельной квартире, может оказаться, допустим, 5—10 человек. Вместе с тем именно зга категория ветеранов и составляет предмет особого внимания. Однако при численности подвыборки в 10 человек никакой дальнейший статистический анализ уже невозможен.
Следовательно, если мы хотим изучить в статистических показателях особенности условий и образа жизни каких-то определенных групп населения, репрезентативная выборка должна быть заменена целевой, в которой численность каждой интересующей нас группы будет достаточна для более основательного анализа. Такая выборка, будучи качественно представительной в отношении целей исследования, не является статистически репрезентативной в отношении генеральной совокупности.
Во многих случаях необходимы именно целевые выборки23.
23 Иногда целевую выборку называют «социологической», в ней обеспечивается представительство по признакам, выявленным в предыдущих социологических исследованиях, а для реализации таких выборок могут использоваться таксономические процедуры (см. ниже: с. 318—322, а также [84; 107].
Особенно это важно в исследованиях экспериментального плана. Скажем, проверяется эффективность введения новой формы организации труда. Ясно, что для этого следует отобрать подразделения, где введена новая организация, и для сравнения — аналогичные, где работа идет по-старому.
Следует гарантировать в выборке равную численность экспериментальных подразделений или организаций и «контрольных», работающих по прежней системе. При этом важно так подобрать эти подразделения, чтобы они были аналогичны по всем существенным характеристикам, кроме факта наличия или отсутствия новой формы организации труда. Формы собственности, профессиональный и квалифицированный состав работников, их половозрастная структура и, возможно, другие показатели должны быть сопоставимы. Решающее значение имеет здесь отнюдь не пропорциональность выборочной доли экспериментальных подразделений фирмы или предприятия в отношении к их доле в генеральной совокупности, но именно качественное представительство экспериментальных и контрольных объектов соответственно цели исследования.
Численность (объем) выборки зависит от уровня однородности или разнородности изучаемых объектов. Чем более они однородны, тем меньшая численность может обеспечить статистически достоверные выводы. Но степень однородности социального объекта зависит, в сущности, от того, насколько детально мы намерены его исследовать.
Практически любой, самый «элементарный» объект оказывается чрезвычайно сложным. Лишь в анализе мы представляем его как относительно простой, выделяя те или иные его свойства. Чем более основательным и детальным будет анализ, чем больше свойств данного объекта мы намерены принять во внимание в их сочетании, а не изолированно, тем больше должен быть объем выборки.
Для решения такого рода задач как раз и необходимы целевые аналитические выборки. В них учитывается не только структура изучаемой совокупности, но и ограничения, накладываемые на объем выборки целями исследования, глубиной анализа проблем.
Используя статистический критерий Стьюдента, можно рассчитать объем выборок в зависимости от заданного уровня доверительного интервала ошибки вывода [227. С. 19—21]. Чем меньше объем сравниваемых подвыборок (пусть это будут ветераны-одиночки и семейные), тем больше должно быть различие каждой пары сопоставляемых статистик (например, процентные различия оценок условий быта теми и другими). Если численность сравниваемых подвыборок неодинакова, за базу определения допустимой ошибки следует брать наименьшую подвыборку.
В зависимости от объема подвыборки существенность процентных различий определяется таблицей:
Объем подвыборок по их численности
Значимая разность в % при ошибке не более 5 %
Объем подвыборок по их численности
Значимая разность в % при ошибке на более 5%
Допустим, что удовлетворительно оценивают условия быта 85% ветеранов-женщин и 79% мужчин, проживающих с семьями, и соответственно 32% женщин и 38% мужчин-одиночек. Разности в процентах составляют здесь: 85—79=6 и 42— 38,4=3,6%. При численности подвыборок до 150 человек и при 5-процентном уровне ошибки эти различия нельзя признать существенными, так как они должны перекрывать 11,5%.
Но разлиния между соответствующими оценками одиночек и семейных будут существенны. Онисоставят для женщин 85—32=53% и79—38=41% для мужчин. Такие различия значимы уже при выборках около 50 человек. Достоверный вывод звучит так: решающей является ситуация проживания ветеранов с семьей или одиноко. В какой мере эти обстоятельства больше переживаются мужчинами или женщинами, сказать трудно; наших данных для этого недостаточно.
Авторы приведенных расчетов отмечают, что выборки на уровне 500 человек позволяют анализировать табт лицы сопряженности с 4 признаками из трех градаций каждый, а выборки в 1000 единиц расширяют возможности уверенного анализа до таблиц с 6 признаками из пяти градаций. Все это при условии обеспечения доверительного интервала, не превышающего 5% стат^сти-чески значимой ошибки.
Общее правило таково: объем выборки при заданном уровне доверительного интервала должен быть не менее чем пК единиц наблюдения, где п — объем под-выборки по столбцу, а К — число столбцов.
Объем выборки зависит также от уровня доверительного интервала допустимой ошибки, каковая, как уже говорилось, задается целесообразной точностью итоговых обобщений: от повышенной до ориентировочной. Однако здесь имеются в виду так называемые случайные ошибки, связанные с природой любых статистических погрешностей. Именно они и вычисляются как ошибки репрезентативности вероятностных выборок.
В. И. Паниотто приводит следующие расчеты репрезентативной выборки с допущением 5-процентной ошибки [199. С. 81].
Объем генеральной совокупности Объем выборки
Объем генеральной совокупности Объем выборки
Для совокупности более 100000 выборка составляет 400 единиц. Если же иметь в виду генеральные совокупности численностью от 5 тыс. и больше, то, по расче там того же автора, можно указать величины фактичес кой ошибки выборки в зависимости от ее объема [200 С. 82], что для нас весьма важно, памятуя, что величин; допустимой ошибки зависит от цели исследования и необязательно должна приближаться к 5-процентном; уровню.
Объем выборки, если генеральная совокупность ≥5000
625…
Фактическая ошибка при данном объема выборки, %
Наряду со случайными возможны ошибки систематического характера. Они зависят от организации выборочного обследования. Это разнообразные смещения выборки в сторону одного из полюсов выборочного параметра.
Объем, выборки определяется аналитическими задачами исследования, а ее репрезентативность — целевой установкой программы. Именно программа задает образ необходимой генеральной совокупности для проведения выборки. Будет ли это все население или особые его структурные образования, все элементы изучаемого объекта или только выделяемые по заданным программой критериям.
Генеральную совокупность составляют все единицы определенного в программе объекта. Теперь .следует обеспечить равную их вероятность попадания в выборочную совокупность.
При небольших по численности генеральных совокупностях применяют случайную бесповторную выборку, где обеспечивают равную вероятность попадания в исследование всех ее единиц по полному их списку из генсовокупности. Имея полный список работников предприятия (например, 2000 человек) и определив объем выборочной совокупности (например, в 2000 человек), устанавливаем шаг выборки делением первого на второе (2000:200) и получаем шаг отбора — каждый 10-й из списка. Здесь важно не допустить систематической ошибки из-за отсутствия в списке, скажем, какого-то подразделения, например работающих в филиале предприятия.
При больших генеральных совокупностях, как это имеет место в опросах населения, используют многоступенчатый отбор по районам, т. е. крупным структурным составляющим генеральной совокупности: регионы, типы поселений, кварталы города. На каждой ступени отбора следует обеспечить требования представительности населения, т. е. обоснованно отобрать регионы так, чтобы не было смещения по какому-то важному параметру (например, по этнонациональному). То же самое и на последующих ступенях отбора. В конечном счете отбор производится опять-таки систематически с установленным шагом отбора по списку граждан (из списков избирателей или иных), списку хозяйств на селе, путем посещения каждой, скажем, 20-й квартиры в списке квартир каждого 50-го дома выделенного квартала города.
Многие обстоятельства усложняют проблему расчета ошибки и нередко могут привести к тому, что формально-статистически репрезентативная выборка’окажется качественно непредставительной.
Итак, качество выборки зависит от трех условий: (а) от меры однородности социальных объектов по наиболее существенным для исследования характеристикам; (б) от степени дробности группировок анализа, планируемых по задачам исследования; (в) от целесообразного уровня надежности выводов из предпринимаемого исследования.
Очень часто малоопытный социолог не улавливает разницы между проблемой ошибки репрезентативности выборки и ошибки вывода из данного конкретного распределения в рамках выборочной совокупйости.
Пусть выборка достаточно репрезентативна и ошибка по тому или иному параметру выборки незначительна. Оценка уровня достоверности вывода по каждому конкретному распределению остается при этом проблемой самостоятельного анализа.24
24 Приемы расчета разнообразных ошибок вывода рассматривает К. В. Кемниц, который подчеркивает, что формально-статистические методы расчета ошибок вывода должныпредваряться «инженерным»
(т. е, содержательным, — В. Я.) изучением распределения [108. С. 4]
Несколько заключительных замечаний. Из сказанного выше может показаться, что обеспечить представительство данных в выборочном обследовании если и удается, то ценой непомерных усилий, разумность затрат которых часто сомнительна. Рекомендуется, во-первых, не отчаиваться и, во-вторых, рассуждать здраво, имея в виду программные цели исследования.
Если перед нами стоит задача выполнить дескриптивное обследование большой общественной значимости, в итоге которого должны быть сделаны заключения относительно генеральной совокупности в целом, следует, конечно, максимально реализовать все требования репрезентативной выборочной процедуры. Затраченные усилия будут не только оправданны, они просто необходимы, так как ошибки в выводах такого исследования недопустимы. Здесь ложная информация опаснее ее отсутствия (достаточно сослаться на ошибки прогнозов исхода выборов вследствие ошибок выборки опросов электората или ошибки в исследованиях рынка).
Если же задачи исследования более скромные, уровень надежности планируемых выводов с точки зрения их статистической точности можно смело понизить, но надо принять все меры к качественному представительству выборочной совокупности. Преувеличенное внимание к формально-статистическим критериям достоверности выводов (и тем более их абсолютизация) за счет качества исходной информации и качества анализа — свидетельство профессиональной неопытности социолога.
Подчеркивая статистическую надежность данных, он вводит в заблуждение и себя, и, хуже того, тех, кто привык верить в убедительность математических расчетов. Нельзя забывать о реальной природе того, что кроется за цифрами и математическими формулами.
Ведь сами исходные характеристики, получаемые исследователем путем опросов или другими способами, лишь условно переводятся в количественные показатели. Часто эти количественные сведения весьма приблизительно отражают существо социальных процессов. Поэтому усилия, направленные на строгость статистического обоснования результатов, приобретают смысл только при условии серьезного качественного анализа проблемы, содержательного ее изучения. Бывает и так, что непредставительные в статистическом смысле данные, многократно повторяемые на разных подвыбо^рках, как раз свидетельствуют об определенной социальной тенденции лучше, чем статистически достоверный вывод, сделанный на одной единственной выборке.
Следует постоянно помнить, что социолог призван сосредоточить внимание именно на существе социальных проблем, активно привлекать к постановке задач исследования других специалистов, практиков и теоретиков, внимательно следить за литературой по широкому кругу вопросов, относящихся к предмету исследования. Наконец, для решения собственно статистических задач, касающихся типа и объема выборки, он прежде всего обязан максимально четко сформулировать конкретные вопросы, подлежащие решению, и уже после этого обращаться к соответствующим расчетам разнообразных статистик.
Как вывести данные менеджеров, у которых более 5 подчиненных, используя подзапрос?
Есть такая задача: Используя таблицу HR.EMPLOYEES, отобразить данные о сотрудниках (имя и фамилия, оклад, идентификатор департамента, номер телефона и e-mail), каждый из которых является менеджером для более 5 подчиненных. Попробовал реализовать вот так, но выходит ошибка:
select first_name, last_name, department_id, phone_number, email from hr.employees where (select manager_id from hr.employees where count(manager_id) > 5)
База данных выглядит вот так:
EMPLOYEE_ID FIRST_NAME LAST_NAME EMAIL PHONE_NUMBER HIRE_DATE JOB_ID SALARY COMMISSION_PCT MANAGER_ID DEPARTMENT_ID 100 Steven King SKING 515.123.4567 17-JUN-03 AD_PRES 24000 — — 90
Решение с помощью трехуровневого Связанного списка
Другим подходом является использование трехуровневого Связанного списка с использованием элементов управления формы , где из исходной таблицы Сотрудники последовательно выбирая Дирекцию и Отдел, можно быстро отобразить всех сотрудников соответствующего отдела в отдельной таблице.
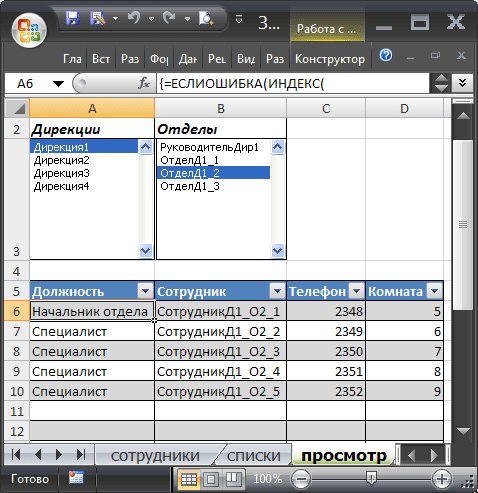
Преимущества использования трехуровневого Связанного списка – субъективны. Кому-то нравится работать с фильтром, кому-то со списками. Работать со списками несколько быстрее и информативнее (выбрав дирекцию, автоматически получим список всех ее отделов). Кроме того, в отличие от фильтра отобранные строки будут помещены в отдельную таблицу — своеобразный отчет, который можно форматировать в стиль отличный от исходной таблицы. В этот отчет можно вынести не все столбцы, а только нужные (хотя после применения фильтра ненужные столбцы можно скрыть).
Основной недостаток – сложность реализации трехуровневого Связанного списка . Но, единожды его создав и поняв принцип работы, этот недостаток в достаточной мере компенсируется.
Алгоритм создания запроса на выборку следующий:
ШАГ 1
Сначала создадим Лист Списки , в котором будут содержаться перечень дирекций и названия отделов (см. файл примера ).
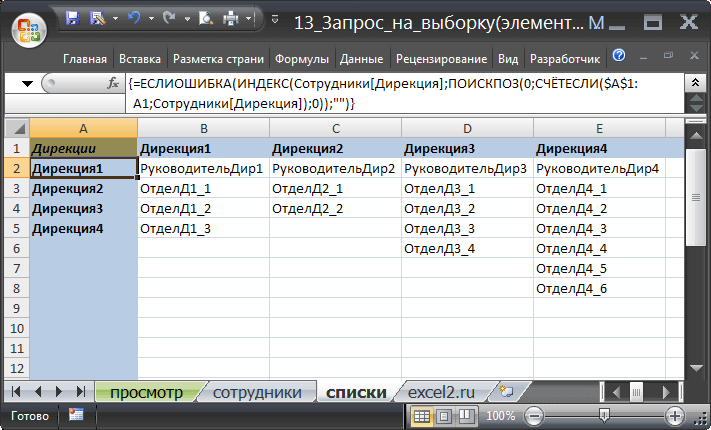
Перечень дирекций (столбец А ) будет извлекаться формулой массива из исходной таблицы с перечнем сотрудников:
Подробности работы этой формулы можно прочитать в статье Отбор уникальных значений .
Перечень отделов (диапазон B 2: E 8 ) будет извлекаться аналогичной формулой массива в соответствующие столбцы на Листе Списки :
=ЕСЛИОШИБКА(ИНДЕКС(Сотрудники[Отдел]; ПОИСКПОЗ(0;ЕСЛИ(B$1=Сотрудники[Дирекция];0;1)+ СЧЁТЕСЛИ($B$1:B1;Сотрудники[Отдел]);0));»»)
ШАГ 2
Теперь создадим Лист Просмотр , в котором будут содержаться перечень сотрудников выбранного отдела и два списка (дирекции и отделы), сформированных на основе Элемента управления форм Список .
Первый список создадим для вывода перечня дирекций. Источником строк для него будет созданный ранее динамический диапазон Дирекции. Свяжем его с ячейкой А1 .
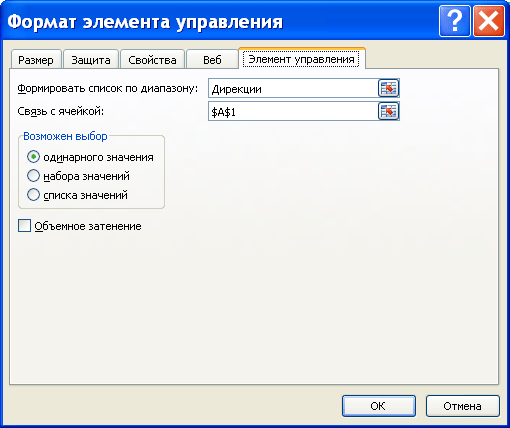
Теперь создадим Динамический диапазон Выбранная_дирекция , который будет содержать название выбранной дирекции:
Также создадим Динамический диапазон Отделы , который будет содержать перечень отделов выбранной дирекции и служить источником строк для второго списка:
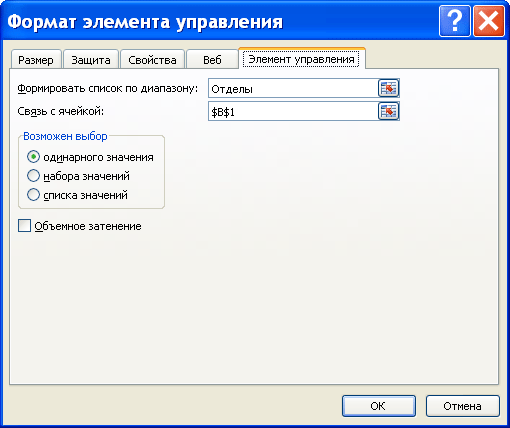
И, наконец, для вывода фамилий сотрудников (ячейка B 6 ), их номеров телефонов и комнат используем зубодробительную формулу:
=ЕСЛИОШИБКА(ИНДЕКС(Сотрудники[Сотрудник]; НАИМЕНЬШИЙ(ЕСЛИ((СТРОКА(Сотрудники[Телефон])* (просмотр!$C$1=Сотрудники[Отдел]))=0;»»; СТРОКА(Сотрудники[Телефон])*(просмотр!$C$1=Сотрудники[Отдел])); СТРОКА(Просмотр[[#Эта строка]; [Должность]])-СТРОКА(Просмотр[[#Заголовки]; [Должность]]))-СТРОКА(Сотрудники[[#Заголовки];[Отдел]]));»»)
Написать программу, делающую выборку сотрудников — VBA
Помогите пожалуйста написать программу. В первых 10 столбцах рабочего листа находятся сведения о сотрудниках фирмы. Причем среди этих сведений имеются сведения о доходах сотрудника. Необходимо написать программу, делающую выборку сотрудников, доход которых заключен между двумя числами, введенными с клавиатуры. Имена полей и их содержимое придумать самостоятельно.
Полученную выборку вывести на второй рабочий лист. Должно получиться по этому примеру.
Type Spisok LastName As String FirstName As String PapaName As String Age As Byte End Type Sub Laba6() Dim sp() As Spisok, i As Integer, g As Integer, n As Integer Sheets(«Лист2»).Select Range(«A1:D12»).Clear Sheets(«Лист1»).Select While Cells(n + 1, 1) <> «» n = n + 1 Wend n = n — 1 ReDim sp(n) For i = 1 To n sp(i).LastName = Cells(i + 1, 1) sp(i).FirstName = Cells(i + 1, 2) sp(i).PapaName = Cells(i + 1, 3) sp(i).Age = Cells(i + 1, 4) Next i sp = sortByLastName(sp, n, True) sp = sortByAge(sp, n, True) j = 2 For i = 1 To n Sheets(«Лист2»).Select Cells(j, 1) = sp(i).LastName Cells(j, 2) = sp(i).FirstName Cells(j, 3) = sp(i).PapaName Cells(j, 4) = sp(i).Age j = j + 1 Next i End Sub Private Function sortByLastName(massive() As Spisok, massiveSize As Integer, key As Boolean) As Spisok() ‘ key = true — по возрастанию ‘ key = false — по убыванию Dim sI As Integer, sJ As Integer, buf As Spisok For sI = 1 To massiveSize — 1 For sJ = 1 To massiveSize — sI If (key) Then If (massive(sJ).LastName > massive(sJ + 1).LastName) Then buf = massive(sJ) massive(sJ) = massive(sJ + 1) massive(sJ + 1) = buf End If Else If (massive(sJ).LastName < massive(sJ + 1).LastName) Then buf = massive(sJ) massive(sJ) = massive(sJ + 1) massive(sJ + 1) = buf End If End If Next sJ Next sI sortByLastName = massive End Function Private Function sortByAge(massive() As Spisok, massiveSize As Integer, key As Boolean) As Spisok() ‘ key = true — по возрастанию ‘ key = false — по убыванию Dim sI As Integer, sJ As Integer, buf As Spisok For sI = 1 To massiveSize — 1 For sJ = 1 To massiveSize — sI If (key) Then If (massive(sJ).Age >massive(sJ + 1).Age) Then buf = massive(sJ) massive(sJ) = massive(sJ + 1) massive(sJ + 1) = buf End If Else If (massive(sJ).Age < massive(sJ + 1).Age) Then buf = massive(sJ) massive(sJ) = massive(sJ + 1) massive(sJ + 1) = buf End If End If Next sJ Next sI sortByAge = massive End Function
ПОЖАЛУЙСТА ПОМОГИТЕ.
Решение задачи: «Написать программу, делающую выборку сотрудников»
Листинг программы
Sub Lab_6() Const COLS = 10 ‘Количество столбцов в базе данных. Dim sp As Variant, rs() As Variant ‘sp — исходный список, rs — результирующая выборка. Dim i As Long, j As Long, n As Long Dim c As Long, k As Long, m As Long ‘Ввод минимум и максимума. Do k = InputBox(«Введите минимум.») m = InputBox(«Введите максимум.») If k > m Then MsgBox «Минимум не должен быть больше максимума.» Loop While k > m ‘Получение исходных данных. sp = Sheets(1).UsedRange.Resize(, COLS) n = UBound(sp) ‘Определили количество записей. ReDim rs(1 To n, 1 To COLS) As Variant ‘Анализ данных. j = 1 For c = 1 To COLS rs(1, c) = sp(1, c) Next c For i = 2 To n If sp(i, 4) >= k And sp(i, 4)
- решить любую задачу по программированию
- объяснить код
- расставить комментарии в коде
- и т.д
8 голосов , оценка 4 из 5
Похожие ответы
- Написать программу в VBA арифметической прогрессии в динамическом массиве
- Написать программу, которая выводит все возможные сочетания из двух цифр!
- Написать программу для вычисления только положительных элементов массива
- Двумерный массив. Как написать код умножения двух матриц
- Возможно ли в строку написать разные команды внутри iif
- Написать функцию нахождения среднего арифметического
- Как написать код программы, подбирающей магический квадрат 5х5 перебором?
- Выборка уникальных дат из строк листа «l1» и помещение их в лист «l3», Не получается. На листе «l3» вставляет
- Выборка INNER JOIN по нескольким ключам из разных таблиц
- Примеры поведения макросов в разных версиях программы «MS Word»
- Закрытие макросом — определенной программы
Все виды студенческих работ на заказ
Для последнего примера важно отметить одну принципиальную
особенность: внешний (основной) запрос управляет работой вложенного подзапроса, т.е. здесь происходит взаимодействие по схеме «сверху вниз» . В частности, при работе подзапроса нужно иметь конкретное значение location_id , которое передается из Следовательно, подзапрос выполняется основного запроса. несколько раз при разных значениях этого параметра. Подзапрос, обладающий такой особенностью, называют связанным (или коррелированным ).
Пример . Сформировать перечень департаментов, в которых отсутствуют сотрудники. SELECT department_id, department_name FROM DEPARTMENTS dps WHERE not EXISTS ( SELECT * FROM EMPLOYEES WHERE department_id = dps.department_id ) Легко заметить, что здесь использован коррелированный подзапрос.
OlegPetrenkoGit / Queries.sql
Save OlegPetrenkoGit/0adb08c24b4f0a03fba9 to your computer and use it in GitHub Desktop.
Sql interview
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
| — 1. Вывести список сотрудников, получающих заработную плату большую чем у непосредственного руководителя |
| SELECT * |
| FROM Employee AS employees, Employee AS chieves |
| WHERE chieves . id = employees . chief_id AND employees . salary > chieves . salary ; |
| — 2. Вывести список сотрудников, получающих максимальную заработную плату в своем отделе |
| SELECT * |
| FROM Employee AS employees |
| WHERE employees . salary = ( SELECT MAX (salary) FROM Employee AS max WHERE max . department_id = employees . department_id ); |
| — 3. Вывести список ID отделов, количество сотрудников в которых не превышает 3 человек |
| SELECT department_id |
| FROM Employee |
| GROUP BY department_id |
| HAVING COUNT ( * ) |
| — 4. Вывести список сотрудников, не имеющих назначенного руководителя, работающего в том-же отделе |
| SELECT * |
| FROM Employee AS employees |
| LEFT JOIN Employee AS chieves ON ( employees . chief_id = chieves . Id AND employees . department_id = chieves . department_id ) |
| WHERE chieves . id IS NULL ; |
| — 5. Найти список ID отделов с максимальной суммарной зарплатой сотрудников |
| WITH dep_salary AS |
| ( SELECT department_id, sum (salary) AS salary |
| FROM employee |
| GROUP BY department_id) |
| SELECT department_id |
| FROM dep_salary |
| WHERE dep_salary . salary = ( SELECT max (salary) FROM dep_salary); |
Как вывести из таблицы список руководителей с количеством их подчиненных?
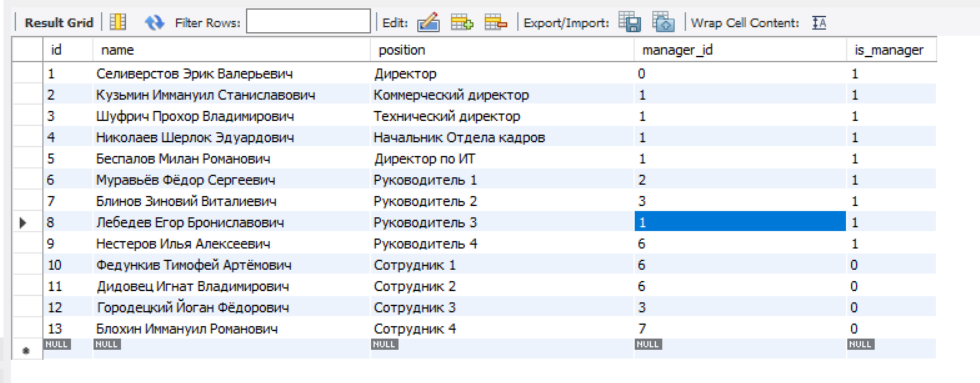
Подскажите, пожалуйста, каким образом можно вывести список руководителей с количеством их подчиненных из таблицы вида:
Получился такой запрос, но проблема в том, что он не выводит тех руководителей, у которых подчиненных нет.
SELECT m.name, m.position, COUNT(e.name) AS number_of_subordinates FROM employees as e JOIN employees as m ON e.manager_id = m.id GROUP BY m.name;
И небольшой сопутствующий вопрос — пытаюсь вывести список вида «Сотрудник — Руководитель», отображаются все записи кроме записи сотрудников, для которых не указаны руководители.
SELECT e.name as Employee, e.position as Position, m.name as Manager FROM employees e, employees m WHERE e.manager_id = m.id;
- Вопрос задан более трёх лет назад
- 1906 просмотров
1 комментарий
Простой 1 комментарий



